SQL옵티마이저란?
사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해주는 DBMS의 핵심엔진이다.
SQL옵티마이저 힌트 사용법
주석 기호에 '+'를 붙인다.
select /*+ INDEX(A 사원_PK)*/
이름, 나이
FROM 사원 A
WHERE 이름 = '홍길동'아래와 같은 방식도 적용가능하다. (하지만 쿼리의 statement를 하드코딩해야하는 상황이라면 줄바꿈 오류가 발생할 수 있어 사용을 지양해야함.)
select --+ INDEX(A 사원_PK)
이름, 나이
FROM 사원 A
WHERE 이름 = '홍길동'힌트 사용시 주의사항
1,2) 힌트안의 인자를 나열할 때 ','(콤마) 사용가능, 단 힌트와 힌트 사이에는 사용불가능
3) 스키마명 명시 하지 않을것
4) 테이블에 ALIAS를 지정했다면 반드시 사용 필수
1)
/*+ INDEX(A 사원_PK) INDEX(B 부서_PK)*/ -> 모두 적용가능
2)
/*+ INDEX(A 사원_PK), INDEX(B 부서_PK)*/ -> 첫번째 힌트만 적용
3)
SELECT /*+ INDEX(SCOTT.사원_PK)*/ -> 무시(스키마명을 명시하면 안됨)
FROM EMP
4)
SELECT /*+ INDEX(사원_PK)*/ -> 무시(Alias를 지정하였으나 사용하지 않음)
FROM EMP E
자주사용하는 힌트 모음
| 분류 | 힌트 | 설명 |
| 최적화 목표 | ALL_LOWS | 전체 처리속도 최적화 |
| FIRST_ROWS(N) | 최초 N건 응답속도 최적화 | |
| 엑세스 방식 | FULL | TABLE FULL SCAN 유도 |
| INDEX | INDEX SCAN으로 유도 | |
| INDEX_DESC | INDEX 역순으로 스캔 유도 | |
| INDEX_FFS | INDEX FAST FULL SCAN으로 유도 | |
| INDEX_SS | INDEX SKIP SCAN으로 유도 | |
| 조인순서 | ORDERED | FROM절에 나열된 순서대로 조인 |
| LEADING | LEADING 괄호에 기술한 순서대로 조인 ex) LEADING(A B) |
|
| SWAP_JOIN_INPUTS | 해시조인시, BUILD INPUT을 명시적으로 선택 ex) SWAP_JOIN_INPUTS(A) |
|
| 조인방식 | USE_NL | NL조인으로 유도 |
| USE_MERGE | 소트 머지 조인으로 유도 | |
| USE_HASH | 해시조인으로 유도 | |
| NL_SJ | NL세미조인으로 유도 | |
| MERGE_SJ | 소트 머지 세미조인으로 유도 | |
| HASH_SJ | 해시 세미조인으로 유도 |
조인방식을 조금 더 정리해보자
1) NL조인 (NESTED LOOPS조인)
프로그램에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행한다.
- 반복문의 외부에 있는 테이블을 선행테이블, 혹은 외부테이블(OUTER TABLE)이라고 하고
- 반복문의 내부에 있는 테이블을 후행테이블, 혹은 내부테이블(INNER TABLE)이라고 한다 .
for OUTER TABLE {
for INNER TABLE {
//......
}
}위와 같이 (중첩 for문과 유사한 방식)
1-1) NL조인 특징
- 선행 테이블(OUTER TABLE)의 조건을 만족하는 행을 추출하여 후행테이블(INNER TABLE)을 읽으면서 조인을 수행한다.
- 선행테이블의 조건을 만족하는 모든행의 수만큼 반복수행한다
- 선행테이블의 조건을 만족하는 수가 많을수록 후행테이블의 작업량이 그만큼 반복됨
- 결과 행의 수가 적은 테이블을 조인 순서상 선행 테이블로 선택해야 한다.
- 랜덤 방식으로 데이터 엑세스하기 때문에 처리범위가 좁은 것의 조건으로 선택하는것이 유리
- NL JOIN 기법은 사용자에게 결과를 바로 보여주므로 온라인 프로그램에 적당한 기법이다.

NL조인이 잘 설명되어 있는 그림이다.
1-2) NL조인 수행 순서
1) 선행테이블에서 조건에 만족하는 첫번째 행을 찾는다
2) 선행 테이블의 조인키로 후행테이블에 조인키가 존재하는지 찾기 위해 조인 시도
3) 후행테이블의 인덱스에 선행테이블의 조인키가 존재하는지 확인
-> 선행테이블의 조인값이 후행테이블에 존재하지 않으면 선행테이블의 데이터는 필터링된다. (조인작업 X)
4) 인덱스에서 추출한 레코드 식별자를 이용하여 테이블 엑세스 -> 인덱스 스캔을 통한 테이블 엑세스
나머지행 1~4번 작업 반복 수행
2) SORT MERGE JOIN
조인컬럼에 인덱스가 없을때, 대량데이터 조인이어서 인덱스가 효과적이지 않을때 옵티마이저는 소트머지 조인이나 해시조인을 선택한다.
2-1) SORT MERGE 조인 수행 순서
1)선행 테이블에서 주어진 조건을 만족하는 행 찾기
2) 선행테이블의 조인키를 기준으로 정렬작업 수행 (선행테이블의 조건을 만족하는 모든행에 대해 수행)
3) 후행테이블에서 주어진 조건을 만족하는 행을 찾음
4) 후행테이블의 조인키를 기준으로 정렬작업 수행(후행테이블의 조건을 만족하는 모든행에 대해 수행)
5) 두 정렬된 결과를 이용하여 조인을 수행하여 조인 성공시 추출버퍼에 넣음
3) HASH 조인
NL JOIN 랜덤엑세스와 SORT MERGE JOIN의 문제점인 정렬작업의 부담을 해결하기 위한 대안
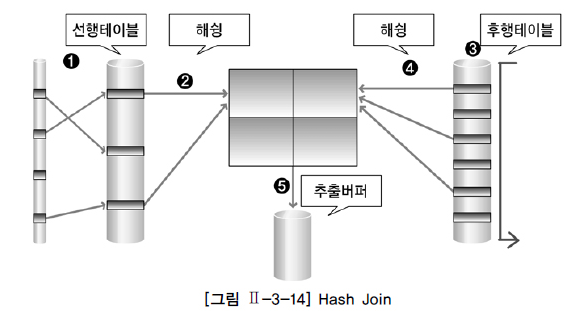
3-1) HASH 조인 수행 순서
1)선행테이블에서 주어진 조건을 만족하는 행 찾기
2) 선행테이블의 조인키를 기준으로 해쉬함수를 적용하여 해쉬테이블(해시맵) 생성 (선행테이블의 조건을 만족하는 모든행에 대해 수행)
3) 후행테이블에서 주어진 조건을 만족하는 행을 찾음
4) 후행테이블의 조인키를 기준으로 해쉬함수를 적용하여 해시테이블을 탐색하면서 조인한다.
5) 조인성공시 추출버퍼에 넣음
※ 참고문헌: (주)디비안 조시형, 친절한 SQL 튜닝
'공부 > 오라클 (Oracle) DB' 카테고리의 다른 글
| [오라클 DB] 현재 세션의 날짜 형식 확인하는 방법, 논리 연산자 진리표 (0) | 2022.02.13 |
|---|---|
| [Oracle] order by와 rownum (feat. 프로그래머스 SQL) (0) | 2022.02.03 |

댓글